毕业论文《基于机器学习的Web异常流量监测系统的设计与实现》
一个人知道自己为什么而活,就可以忍受任何一种生活。
—- 尼采
前言
首先还是要感谢我所参考了的文章的作者们,在我前期一无所知的时候对我帮助很大,虽然论文现在看起来技术含量不是很大,但是还是要感谢他们。
花费的时间主要是前期对所涉及环境的选择有点迷茫(ELK、kafka、Zookeeper、HDFS、Spark、Flume、Tcpdump…..),以及对熟悉分布式环境的搭建以及使用,后期代码的编写倒没用多少时间。
环境最终选择了Spark + HDFS + Flume + MySQL + Django,由Python编写分析代码,机器学习方面采用的三种算法为(LGS、NB、SVM)。
写完之后查重发现好像已经有人写过相似的论文…囧,不过当初也没有查,网上找了下相关的资料就直接开始写了
架构是参考【1】,在基础上稍微改动了一下,代码参考了正则表达式方面。
系统设计与实现
功能设计
系统功能包括用户管理、实时日志分析、离线日志分析等功能,并通过搭建Django站点为用户提供可视化界面,如图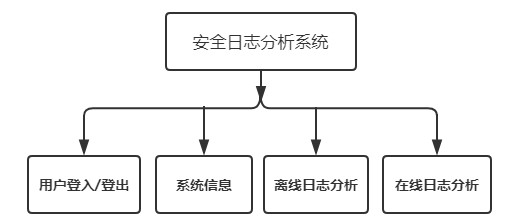
硬件架构
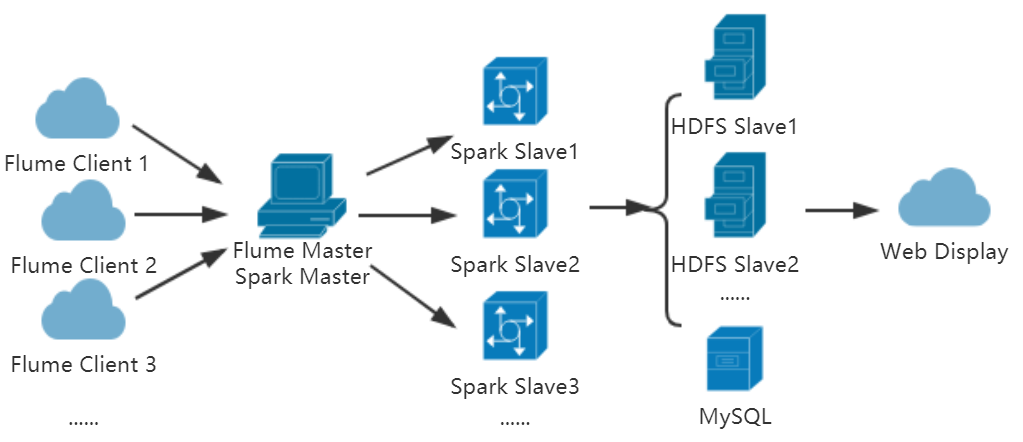
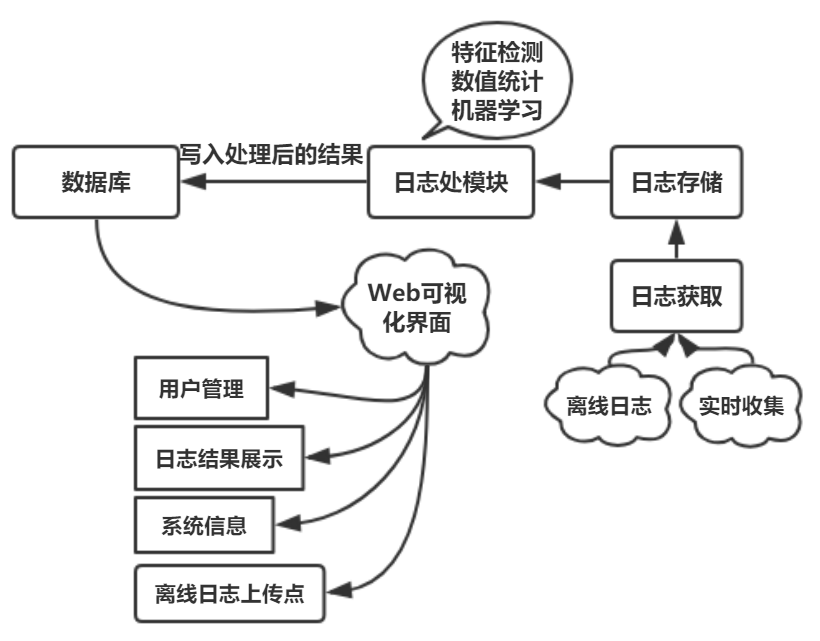
本系统使用Flume对日志进行分布式收集,Spark和HDFS对所收集的日志进行分布式计算与存储,以上框架都是分布式的。使用MySQL对结果进行存储,最后通过Web可视化界面对结果进行展示以及提供离线日志上传点.
本次论文系统使用了三台CentOS7,分别为Master(192.168.10.100)、Slave01(192.168.10.101)、Slave02(192.168.10.102)。
功能说明:
- Master作为HDFS的控制端,Slave01与Slave02作为数据存储端;
- Master、Slave01、Slave02三台机器都作为Spark计算节点;
- Master上搭建Web站点,作为日志的生产端;
- Master搭建Flume,对Web日志进行收集并将其传输到HDFS;
- Slave01上搭建MySQL数据库与Django可视化界面,负责对结果进行存储与展示;
主框架设计
算法结构
本系统使用了三种机器学习算法对流量进行识别:逻辑回归、支持向量机和朴素贝叶斯。同时利用传统的正则表达式对其进行预处理,相比较下正则表达式虽然有一定的拘束性,但对已知攻击的识别还是较为有效的。
在数值统计模块,可对爆破、目录遍历等时序有关的攻击进行统计,本例中仅对IP以及请求资源的访问频率进行了计算。
除此之外,本系统通过正则匹配、数值统计与机器学习三大模块进行识别处理,在机器学习模块中,三种机器学习算法实行投票制度,三种中两种检测出异常则为异常,最后得出一条日志的识别结果,最后将检测结果存储到数据库。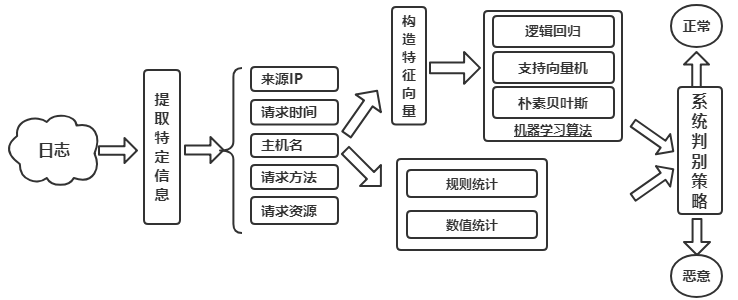
系统实现
日志获取
其中,日志获取的流程有两种途径,Web离线日志分析界面负责接收访问用户上传的离线日志,而Flume负责获取Web站点实时生成的日志。
日志预处理
随机抽取一条日志,如图
此为Apache日志格式的默认配置,通过查阅配置文件得到其格式依次为:远程IP - 用户名 - 时间 请求主体 响应码 字节长度 请求来源 来源客户端信息。
若要对其进行分析识别,首先要对各个字段进行提取,我们利用正则来提取相应字段(方式为?P
日志存储
HDFS负责日志存储,自动将获取(用户提交的离线日志和实时)的日志被分到各个节点上。
正则匹配
Spark负责对日志中的各条数据进行提取、特征匹配、统计特定数值,并通过机器学习模型对其中的关键数据点进行识别并分类;
通过部分攻击关键字来识别常见的已知Web攻击,包括SQL注入漏洞、跨站脚本攻击(XSS)、代码注入、命令执行、XML外部实体注入等常见的Web漏洞,部分正则如图所示
数值统计
在海量的日志文本中,包含了大量信息,包括用户请求的资源、请求者的IP以及在请求中携带的攻击载荷(因为在部分中间件的默认配置中,不会记录POST数据,所以此仅对GET数据做分析),这些信息表现出的特征可以非常明确地表达请求方所携带的网络动作,但有些动作通过传统的防御方法是难以发现的,攻击者通过对载荷进行变种,就很轻松的绕过了传统的防御及检测方法,例如正则表达式、黑白名单等。
例如在一定时间内请求者的IP数量、对统一资源的请求次数、不同状态码的请求比例,部分行为如果符合攻击的行为,我们就可以通过统计来进行预判断。
例如下列表中列举的常用的基于数只统计的方式来发现潜在异常行为的一些统计方法:
[1] 访问次数统计(爆破)
[2] 访问深度扫描几大量非200请求(站点遍历)
[3] GET、HEAD请求比(站点遍历)
[4] 非静态文件访问比(DDOS攻击)
在实现中只进行了一定时间内IP与请求资源访问频率的计算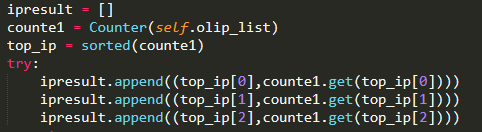
特征化向量
使用机器学习算法的前提是构造好特征向量,在提取完日志中感兴趣的部分后,我们需要对其进行特征化,主要是针对记录中的请求参数、referer以及user-agent,一切的安全问题都体现在“输入输出”上,这三部分都是用户可控并且可以注入攻击载荷的地方。
在特征化向量这块,我们先使用N-Gram将文本向量化,对于下面这条数据:
‘‘
我们通过长度N为3,滑动窗口为1将文本分割为3-Gram序列,如图
结果如图所示
这里的长度是经过较多次数训练的对比最后才取了3,不同长度的N-Gram序列对不同算法识别以及预测都有影响,所以为了提高算法的精准度,可以针对不同算法来选择合适的特征向量方法,这里仅以此来举例。
下一步要把3-Gram序列转化成向量,通过TF-IDF作为特征方式,将序列以数字矩阵的方式输出,然后再交给算法进行识别。
TF-IDF(term frequency–inverse document frequency,词频与逆向文件频率),TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库的重要程度。TF为“词频”,也就是出现次数最多的词。IDF叫做“逆文档频率”,如果某个词比较少见但是文章中多次出现,可能就反映了文章的特性,在统计学语言表达,要对每个词分配一个权重,较少见的词汇会给予较大的权重,它的大小与一个词的常见程度成反比。将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。


通过TfidfVectorizer方法进行进行矢量化,接着调用vectorizer.fit_transform计算出payload的TF-IDF特征矩阵,如图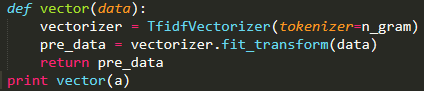
输出格式如图所示: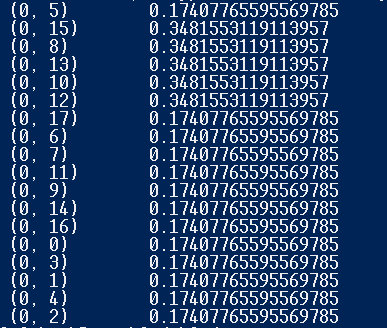
在特征矩阵中有三个元素[(i,j),weight],i对应集合中的文档编号,j对应词片编号,weight表示tf-idf值。
训练模型
在完成特征化向量后,我准备了两份数据集,分别是HTTP流量中的白样本和黑样本,数据集收集了常见的攻击payload,包括:SQLi、XSS、RCE、Code Injection、目录遍历等Payload,我们使用这两份数据集来训练检测模型。
黑样本,如图:
白样本,如图:
然后读取每一列,去除空白符以及对其进行url解码,如图所示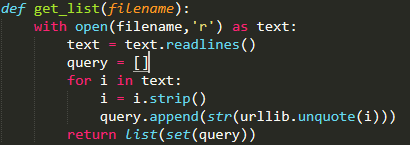
载入数据集后,我们需要对数据进行打标,我们定义正常的数据为0,异常的数据为1,如图所示。
使用train_test_split将数据进行切分,切分为训练数据与测试数据,测试数据占全部的20%,用来测试模型精准度,如图所示:
接着实例化算法模型,对数据进行训练,并打印出模型的精准度,如下两图所示: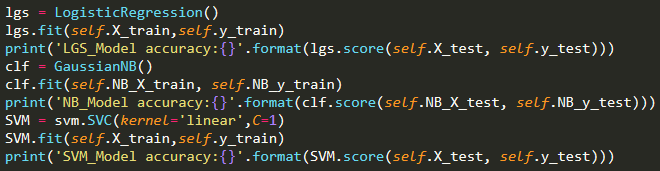

基本达到了80%以上,接下来我们使用算法模型对未知的攻击进行预测,如图4-22所示:(在这应该采用经过混淆的Payload作为演示的)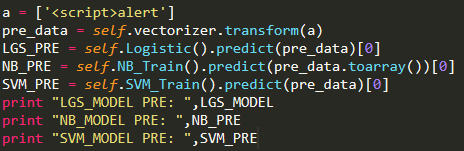
查看三种算法模型的预测结果,如图所示。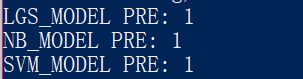
三种模型都检测其为异常数据,投票通过,判定此条日志为恶意流量。
然后通过使用joblib方法来将我们训练后的模型进行保存,如图所示: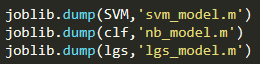
在下次进行预测时,直接加载训练好的模型文件,调用predict方法对未知攻击进行预测即可,如图所示。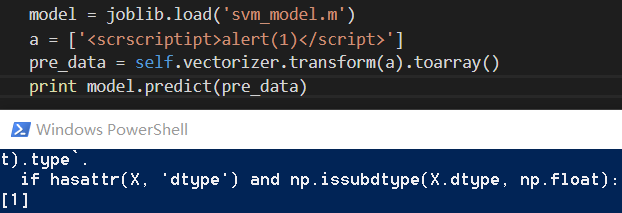
在预测时,如果当前文件夹下训练模型不存在,会提示“正在从HDFS中下载模型,请确认存在后重新运行”,直到查看当前文件夹下存在三种模型后,重新运行即可。如果在HDFS中不存在此三种模型文件会提示“你需要训练并上传模型”,代码如图4-26所示。
结果存储
在Slave01上搭建的MySQL数据库,负责对分析的结果进行保存,MySQL中存在Analyse数据库,拥有offline、online、user三张表(identifyapp_为Django项目表前缀),分别为离线数据表、在线数据表、用户表(其他表为Django自动生成),如图所示。
offline数据表用于存储离线日志的分析结果,一个日志文件对应一条记录。其中包括文件名、日志条数、起止时间、访问量最高的前3个IP、访问量最高的前3条URL、访问条数、攻击条数、攻击者的地理位置信息以及恶意payload,如图所示。
online数据表负责存储对在线日志分析的结果,包括访问量最高的前3个IP、访问次数、攻击次数、攻击者的地理位置信息以及恶意payload,如图所示。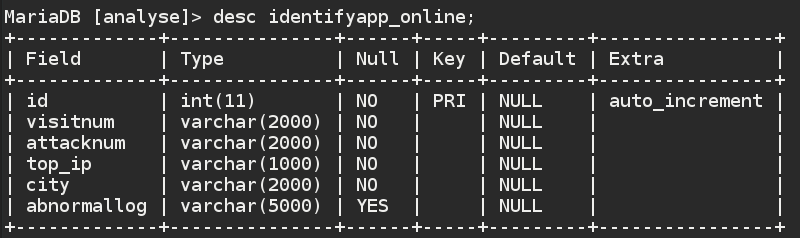
user数据表存储Django可视化界面的管理员信息,各字段如图所示: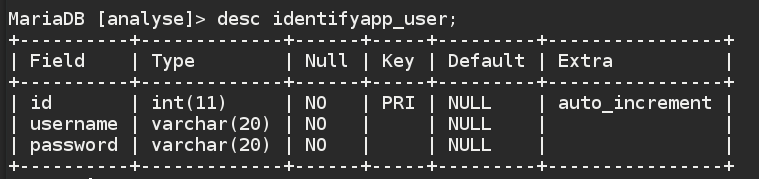
结果可视化
登录界面如图:
后台用户管理界面还是Django的默认用户管理页面,如图所示。
离线日志分析
离线日志分析,用户需要在上传点上传日志,如图所示
在等待分析后会跳转到analyse页面,展示分析结果,分别为,日志文件基本信息,包括文件名、日志行数、日志时间段、请求总数、疑似攻击日志总数,如图所示。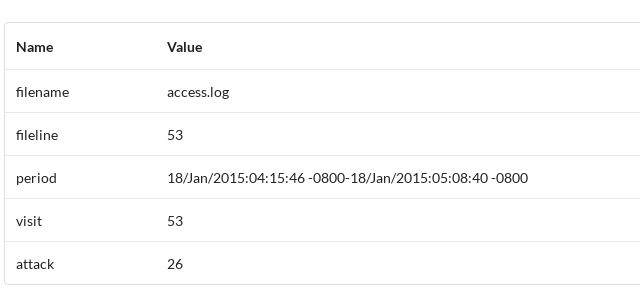
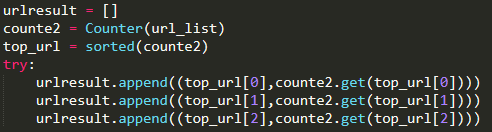
访问量最高的3个IP(测试IP),如图所示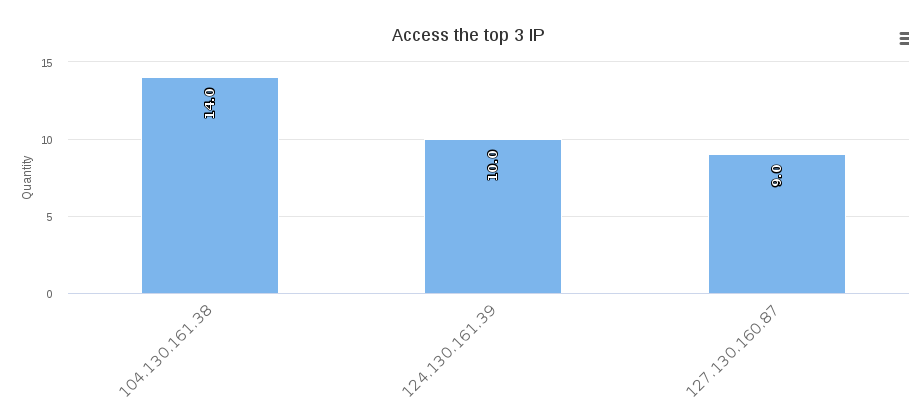
访问量最高的3条URL(测试URL),如图所示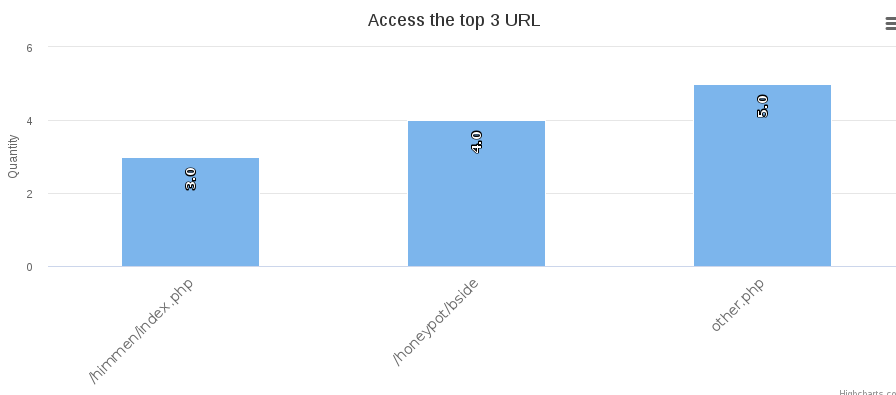
异常日志信息展示(忘记加常见的user-agent了),如图所示
根据TOP3 IP的数量,生成热点图,如图所示。
在线日志分析
分析报表包括:总访问条数、受攻击条数、恶意payload以及攻击源。
启动脚本后Spark开始循环监听HDFS上的online文件夹,如图所示。
当用户访问站点后,站点产生日志,Spark抓取到HDFS中的由flume传递过来的站点日志开始分析,如图所示。
当分析完一部分后,将数据写入MySQL数据库,这是一个持续的过程,Spark只要接收到新日志的产生,就对其进行分析计算,如图所示。
我们在数据库中查看数据,也已成功写入,如图所示
Web站点的实时分析模块会自动读取更新的数据,以动态线条展示出攻击,如图所示。
IP访问频率,如图所示。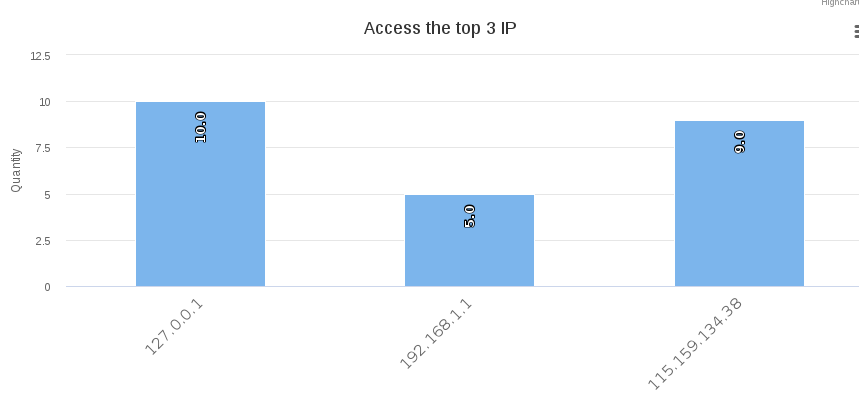
疑似攻击的特定日志,如图
访问频率TOP3 IP的地理热点图,如图
不足以及要改进的地方
我发现Spark streaming更适合离线分析,监听HDFS中的离线文件夹,当检测到有新文件传入时,读取其中的内容。
而在线分析应该采用kafka做消息总线,当前采用Flume以所产生的消息的数量而生成文件这种做法丢包太严重了,若采用kafka的话,Flume直接将数据发送至kafka,然后交于节点计算即可。
参阅文章
1、Web日志安全分析系统实践
2、基于大数据和机器学习的Web异常参数检测系统Demo实现
3、payloads
4、pyspark.streaming module